1. 简介
正交试验法是研究多因素、多水平的一种试验法,它是利用正交表来对试验进行设计,通过少数的试验替代全面试验,根据正交表的正交性从全面试验中挑选适量的、有代表性的点进行试验,这些有代表性的点具备了“均匀分散,整齐可比”的特点。
正交实验法设计测试用例,基本步骤如下:
- 提取测试需求功能说明,确定因素数和水平数
- 根据因素数和水平数确定n值
- 选择合适的正交表
- 根据正交表把变量的值映射到表中,设计测试用例数据集
2、Python实现逻辑详解
参考如上步骤,使用Python实现了使用正交表自动设计裁剪测试用例的完整流程。支持Python版本为 2.7, 3.7。
初始化正交表,解析构造为可用的正交表对象数组 (数据来源:http://support.sas.com/techsup/technote/ts723_Designs.txt)
分别计算m(水平数),k(因素数目),n(实验次数)值
m=max(m1,m2,m3,…)
k=(k1+k2+k3+…)
n=k1*(m1-1)+k2*(m2-1)+…kx*x-1)+1
查找匹配正交表,先查询是否有完全匹配的正交表数据,否则简单处理,只返回满足>=m,n,k条件的n最小数据,暂未做复杂的数组包含校验及筛选逻辑(后续待优化)
使用查找到的正交表数据,裁剪生成测试集。支持两种用例裁剪模式,取值0,1
- 0 宽松模式,只裁剪重复测试集
- 1 严格模式,除了裁剪重复测试集外,还裁剪含None测试集(num为允许None测试集最大数目)
完整代码如下:
1 | # encoding: utf-8 |
3.示例demo
我们复用之前写过的豆瓣电影搜索接口,针对这个接口编写了一个正交表生成裁剪用例Demo (接口文档地址:https://developers.douban.com/wiki/?title=movie_v2#search)
- 首先我们看到,这个接口支持四个参数q,tag,start,count
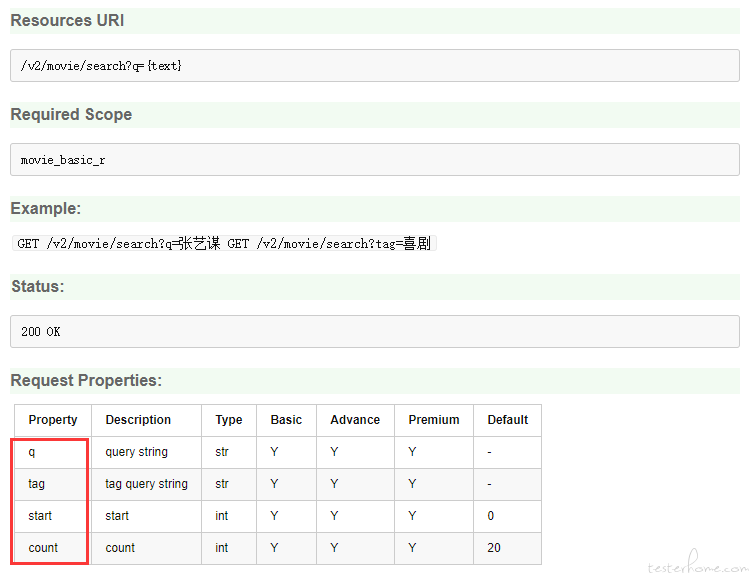
- 针对每个参数分别设计了一些测试集,如果使用原来的组合方式生成测试用例条数为每个参数笛卡尔乘积 (8 * 6 * 3 * 3,而使用正交表生成的测试用例数目为7,大大削减了无效重复的测试条目,提升测试效率
脚本如下:
1 | # encoding: utf-8 |
4. 后续计划
- 判定表查询逻辑优化
- 测试用例集裁剪优化
5. 参考文档
测试用例设计-正交实验法详解:
https://wenku.baidu.com/view/a54724156edb6f1aff001f79.html用正交实验法设计测试用例:http://blog.csdn.net/fangnannanf/article/details/52813498
Dr. Genichi Taguchi 设计的正交表:http://www.york.ac.uk/depts/maths/tables/orthogonal.htm
Technical Support com:http://support.sas.com/techsup/technote/ts723_Designs.txt
若你觉得我的文章对你有帮助,欢迎点击上方按钮对我打赏
扫描二维码,分享此文章